1、 一个二进制$X$发出符号集为${-1, 1}$,经过离散无记忆信道传输,由于信道中噪音的存在,在接收端$Y$收到符号集为${-1, 1, 0}$。已知$P(x=-1)=\frac{1}{4}$,$P(x=1)=\frac{3}{4}$,$P(y=-1|x=1)=\frac{4}{5}$,$P(y=0|x=-1)=\frac{1}{5}$,$P(y=1|x=1)=\frac{3}{4}$,$P(y=0|x=1)=\frac{1}{4}$,求条件熵$H(Y|X)$ ()
A 0.2375
B 0.3275
C 0.5273
D 0.5372
解析:
\begin{split}
\because\quad H(X|Y) &=-\sum P(X, Y)\log P(Y|X) \\
&= -\sum P(Y|X)P(X)\log P(Y|X)
\end{split}
\begin{split} \therefore\quad H(X|Y)&=-(P(y=-1|x=-1)P(x=-1)\log P(y=-1|x=-1) \\
& + P(y=0|x=-1)P(x=-1)\log P(y=0|x=-1) \\
& + P(y=1|x=1)P(x=1)\log P(y=1|x=1) \\
& + P(y=0|x=1)P(x=1)\log P(y=0|x=1)) \\
& =-(\frac{4}{5}\times\frac{1}{4}\times\log\frac{4}{5} + \frac{1}{5}\times\frac{1}{4}\times\log\frac{1}{5} + \frac{3}{4}\times\frac{3}{4}\times\log\frac{3}{4} + \\ & \frac{1}{4}\times\frac{3}{4}\times\log\frac{1}{4}) \\
&\approx -(-0.01938-0.03495-0.07028-0.11289)=0.2375
\end{split}
答案:A
2、 下列哪个不属于CRF模型对于HMM和MEMM模型的优势
A 特征灵活
B 速度快
C 可容纳较多上下文信息
D 全局最优
解析:
HMM(Hidden Markov Model, 隐马尔可夫模型)是对转移概率和表现概率直接建模, 统计共现概率。
MEMM(Maximum Entropy Markov Model, 最大熵马尔可夫模型)是对转移概率和发射概率建立联合概率,统计时统计的时条件概率, 但由于MEMM只在局部做归一化,故容易陷入局部最优。
CRF(Conditional Random Field,条件随机场)统计了全局概率。再做归一化时考虑了数据在全局的分布,而不是仅仅只做局部归一化,这样解决了MEMM中的标记偏置(Label Bias)的问题。
CRF没有HMM那样严格的独立性假设条件,因而可以容纳任意的上下文信息,特征设计灵活。CRF需要训练的参数更多,与MEMM和HMM相比,它存在训练代价大、复杂度高的缺点。
转移概率:给定的马氏链在某时刻处于某一状态,再经若干时间达到另一状态的条件概率。
表现概率:观察变量的条件概率,亦称发射概率。
共现概率:
答案:B
3、 模式识别中,不属于马氏距离较之于欧式距离的优点是()
A 平移不变性
B 尺度不变性
C 考虑了模式的分布
解析:
马氏距离(Mahalanobis Distance)是由印度统计学家马哈拉洛比斯提出的,表示数据的协方差距离,是一种有效的计算两个未知样本集相似度的方法。与欧式距离不同的是,马氏距离考虑到各种特性之间的关系并且是尺度无关的(scale-invariant),即独立于测量尺度。
对于一个均值为$\mu=(\mu_1, \mu_2, \cdots, \mu_p)^T$, 协方差矩阵为$\Sigma$的多变量向量为$x=(x_1, x_2, \cdots, x_p)^T$, 其马氏距离为:
\begin{equation}
D_M(x) =\sqrt{(x-\mu)^T\Sigma^{-1}(x-\mu)}
\end{equation}
对于两个变量$x$和$y$, 其协方差计算公式:
\begin{equation}
cov(x, y) = \mathbb{E}(x-\mathbb{E}(x))(y-\mathbb{E}(y))
\end{equation}
对于含有$n$个变量(或属性)($c_1, c_2, \cdots, c_n$)的数据集,则可得协方差矩阵:
\begin{equation}
\Sigma=
\begin{bmatrix}
cov(c_1, c_1) & cov(c_1, c_2) & \cdots & cov(c_1, c_n) \\
cov(c_2, c_1) & cov(c_2, c_2) & \cdots & cov(c_2, c_n) \\
\vdots & \vdots & \ddots & \vdots \\
cov(c_n, c_1) & cov(c_n, c_2) & \cdots & cov(c_n, c_n)
\end{bmatrix}
\end{equation}
如果协方差矩阵为单位阵,则马氏距离就是欧式距离;如果协方差矩阵为对角阵,此时称马氏距离为正规化的欧式距离。
马氏距离的优点:
马氏距离不受量纲影响:两点之间的马氏距离与原始数据的测量单位无关;
由标准化数据和中心化数据计算的二点之间的距离相同;
马氏距离可以排除变量之间的相关性的干扰。
欧式距离特性有:平移不变性、旋转不变性。
马式距离特性有:平移不变性、旋转不变性、尺度缩放不变性、不受量纲影响的特性、考虑了模式的分布。
答案:A
4、 以下()不属于线性分类器最佳准则。
A 感知器准则函数
B 贝叶斯分类
C 支持向量机
D Fisher准则
解析:
线性分类器有三大类:感知器准则函数、SVM、Fisher准则。贝叶斯分类器不是线性分类器。
感知器准则函数:准则函数以使错分类样本到分界面距离之和最小为原则。优点是通过错分类样本提供的信息对分类器函数进行修正。
支持向量机 :基本思想是在两类线性可分条件下,所设计的分类器界面使两类之间的间隔为最大,它的基本出发点是使期望泛化风险尽可能小(使用核函数可解决非线性问题)。
Fisher 准则 :更广泛的称呼是线性判别分析(LDA),将所有样本投影到一条原点出发的直线,使得同类样本距离尽可能小,不同类样本距离尽可能大,具体为最大化“广义瑞利商”。
答案:B
5、 下面有关分类算法的准确率、召回率和$F1$值的描述,错误的是:
A 准确率是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率
B 召回率是指检索出相关文档数和文档库中所有相关文档数的比率,衡量的是检索系统的查全率
C 正确率、召回率和$F1$值取值都在$0$和$1$之间,数值越接近$0$,查准率和查全率越高
D 为了解决准确率和召回率冲突的问题,引入了$F1$分数
解析:
这里我们使用文档分类作为示例来阐述准确率、精准率、召回率、$F1$和$AUC$。
假设文档库含有$n$篇文档,这些文档可分为$k$类,每类文档具有$m_k$篇文档。设有某算法可对该文档库进行分类,每类正确归档数记为$c_k(c_k <= m_k)$。
准确率(Accuracy)即是该算法分类正确的文档占所有文档库的比率。
\begin{split}
acc = \frac{\sum_{i = 1}^{k}c_k}{\sum_{i = 1}^{k}m_k}\times 100\% = \frac{\sum_{i = 1}^{k}c_k}{n} \times 100\%
\end{split}
其中$n=\sum_{i = 1}^{k}m_k$。
在介绍其他概念之前,需要引入基于二分类的混淆矩阵。实际上,多分类问题可以划分为多个二分类问题。具体地,在多分类问题中,对某一类别$k_i(i=1,2,\cdots,k)$, 若该算法得到的类别标签属于该类别,则分类正确;若由算法得到的分类标签属于其他类别,则分类错误。由此得到了$k_i$类和其他类的二分类问题。
混淆矩阵定义如下:
| 预测值0 | 预测值1 | |
|---|---|---|
| 真实值0 | TN | FP |
| 真实值1 | FN | TP |
我们将当前所关注的分类类别的数据项称之为正例,而不受当前关注的类别的数据项称之为负例。则有:
TN:算法预测为负例(N),实际上也是负例(N)的个数,即算法预测对了(True);
FP:算法预测为正例(P),实际上是负例(N)的个数,即算法预测错了(False);
FN:算法预测为负例(N),实际上是正例(P)的个数,即算法预测错了(False);
TP:算法预测为正例(P),实际上也是正例(P)的个数,即算法预测对了(True)。
于是精准率(Precision)、召回率(Recall)和$F1$值定义如下:
\begin{equation}
prec = \frac{TP}{TP+FP}
\end{equation}
\begin{equation}
recall = \frac{TP}{TP+FN}
\end{equation}
\begin{equation}
F1 = \frac{2\times prec \times recall}{prec + recall}
\end{equation}
AUC被定义为ROC曲线下的面积。诸如逻辑回归这样的分类算法而言,通常预测的都是一个概率值,我们会认为设置一个阈值,超过这个阈值,就预测为其中一类,不超过这个阈值,定义为另外一类。于是,不同的阈值就对应了不同的假正率和真正率,于是通过不同的阈值就形成了假正率和真正率序列,它们就可以在直角坐标系上通过描点成为光滑曲线,这个曲线就是 ROC 曲线。
横坐标:假正率(False positive rate, FPR),预测为正但实际为负的样本占所有负例样本的比例。
\begin{equation}
FPR=\frac{FP}{TN+FP}
\end{equation}
纵坐标:真正率(True positive rate, TPR),这个其实就是召回率,预测为正且实际为正的样本占所有正例样本的比例。
\begin{equation}
TPR=\frac{TP}{TP+FN}
\end{equation}
答案:C
6、 一下几种模型方法属于判别式模型(Discriminative)的有()
(1)混合高斯模型
(2)条件随机场模型
(3)区分度模型
(4)隐马尔可夫模型
A 2,3
B 3,4
C 1,4
D 1,2
解析:
常见的判别式模型有:
Logistic Regression(LR,逻辑回归)
Linear Discriminative Analysis(LDA,线性判别分析, Fisher准则)
Support Vector Machine(SVM,支持向量机)
Boosting(集成学习)
Conditional Random Field(CDF, 条件随机场)
Linear Regression(LR, 线性回归)
Neural Networks(NN, 神经网络)
常见的生成模型:
Gaussian Mixture Model(GMM,高斯混合模型以及其他类型的混合模型)
Hidden Markov Model(HMM,隐马尔可夫模型)
Naive Bayies(朴素贝叶斯)
Averaged One-Dependence Estimators (AODE,平均单依赖估计)
Latent Dirichlet Allocation(LDA主题模型)
Restricted Boltzmann Machine(RBM,受限玻尔兹曼机)
答案:A
7、你正在使用带有L1正则化的logistic回归做二分类,其中$C$是正则化参数,$w_1$和$w_2$是$x_1$和$x_2$的系数。当你把$C$值从$0$增加到非常大的值时,下面哪个选项是正确的?
A 第一个$w_2$成了$0$,接着$w_1$也成了$0$
B 第一个$w_1$成了$0$,接着$w_2$也成了$0$
C $w_1$和$w_2$同时成了$0$
D 即使在$C$成为最大值之后,$w_1$和$w_2$都不能成为$0$
解析:
通过图1可以看出$w_1$和$w_2$同时成了$0$
import numpy as np
import numpy as np
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax1 = Axes3D(fig)
L1 = 1
W1 = np.linspace(-3, 3, 60)
W2 = np.linspace(-5, 5, 60)
C = L1 / (abs(W1) + abs(W2))
ax1.scatter3D(W1, W2, C)
ax1.plot3D(W1, W2, C, 'red')
ax1.set_title("$L1=C*(|w1|+|w2|)$")
ax1.set_xlabel("$w_1$")
ax1.set_ylabel("$w_2$")
ax1.set_zlabel("$C$")
plt.show()
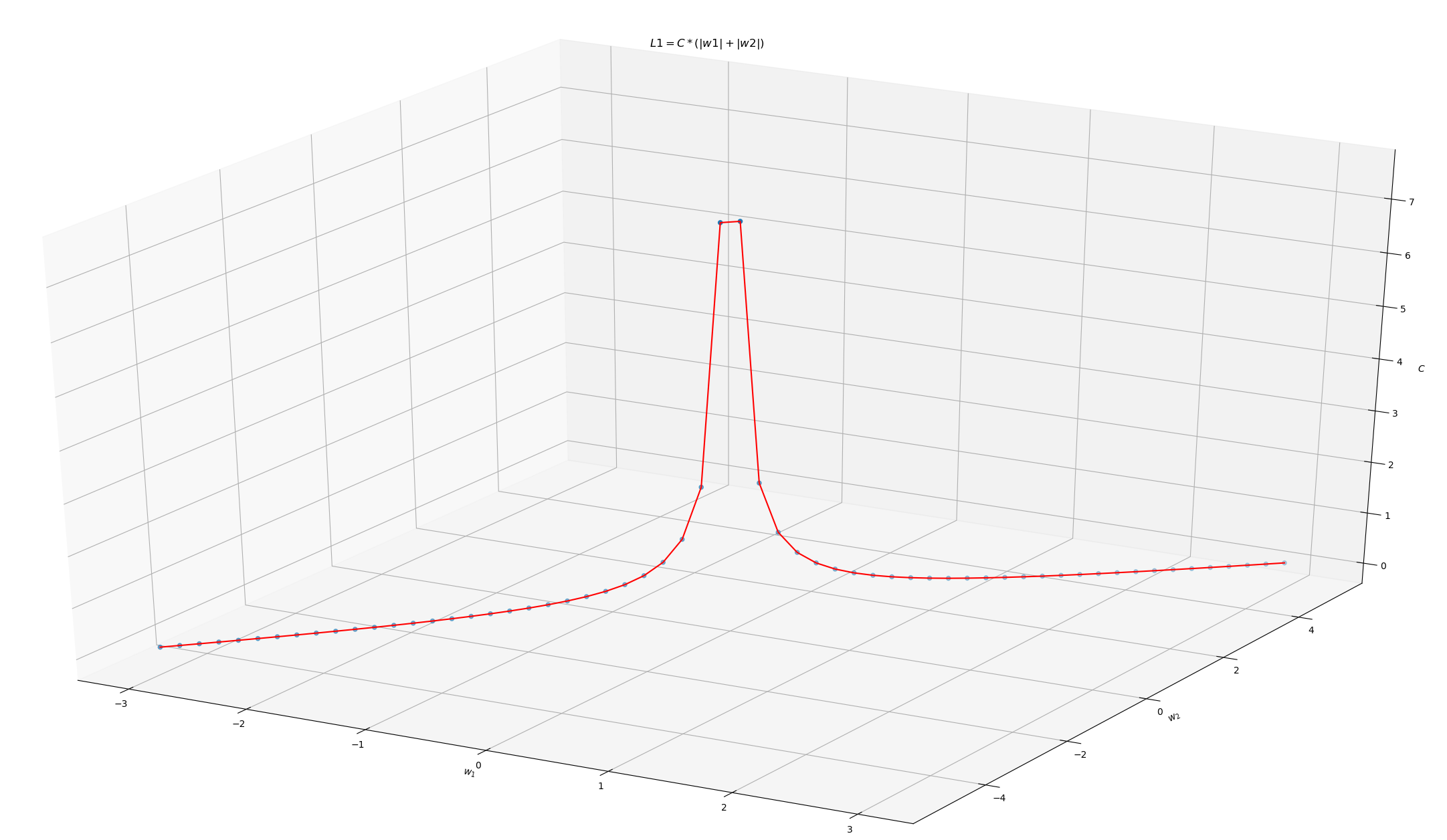 图1 L1正则化函数图像
图1 L1正则化函数图像答案:C
8、下列哪个不属于常用的文本分类的特征选择算法?
A $\chi^2$检验值
B 互信息
C 信息增益
D 主成分分析
解析:
常用的特征选择方法:
(1)DF(Document Frequency,文档频率):统计特征词出现的文档数量,用来衡量特征词的重要性;
(2)MI(Mutual Information,互信息法):用于衡量特征词与文档类关系的信息量。如果某个特征词的频率很低,那么互信息得分就会很高。反之,如果该特征词的频率很高,则互信息得分会很低。因此互信息法倾向低频的特征词;
(3)IG(Information Gain,信息增益法):在某个特征词的缺失与存在的两种情况,根据语料中前后信息的变化来衡量特征词的重要性。
(4)$\chi^2$检验法:利用统计学中“假设检验”的基本思想。首先假设特征词与类别不直接相关,如果利用$\chi^2$分布计算出的检验值偏离阈值越大,那么更有信心否定原假设,接受原假设的备择假设:特征词与类别有着很高的关联度。
(5)WLLR(Weighed Log Likelihood Ration,加权对数似然比);
(6)WFO(Weighted Frequency and Odds):加权频率和可能性。
答案: D
9、下列不是SVM核函数的是()
A 多项式和函数
B logistic核函数
C 径向基核函数
D Sigmoid核函数
解析:
SVM核函数包括线性核函数、多项式核函数、径向基(RBF)核函数(Guassian核函数)、幂指数核函数、拉普拉斯核函数、ANOVA核函数、二次有理核函数、多元二次核函数、逆多元二次核函数以及Sigmoid核函数。
根据泛函有关理论,只要一种函数$\kappa(x_i, x_j)$满足Mercer条件,它就对应某一种变换空间的内积。
Mercer定理:任何半正定的函数都可以作为核函数。所谓半正定的函数$f(x_i, x_j)$,是指对训练数据的集合$(x_1, x_2, \cdots, x_n)$定义一个由元素$a_{ij}=f(x_i, x_j)$组成的矩阵。显然,这个矩阵的规模是$n \times n$。如果该矩阵是半正定的,则$f(x_i, x_j)$就称为半正定函数。
常见的核函数:
(1)线性核函数
\begin{equation}
\kappa(x, z) = <x, z>
\end{equation}
(2)多项式核函数
\begin{equation}
\kappa(x, z) = (<x, z> + 1)^d, r\in Z^+
\end{equation}
(3)RBF核函数
\begin{equation}
\kappa(x, z) = e^{-\frac{\left||x-z\right||^2}{2\sigma^2}}, \sigma=R-\{0\}
\end{equation}
(4)幂指数核函数
\begin{equation}
\kappa(x, z) = e^{-\frac{\left||x - z\right||}{2\sigma^2}}
\end{equation}
(5)拉普拉斯核函数
\begin{equation}
\kappa(x,z) = e^{-\frac{\left||x - z \right||}{\sigma}}
\end{equation}
(6)ANOVA核函数
\begin{equation}
\kappa(x, z) = \sum_{k = 1}^n e\left(\sigma(x^k - z^k)^2 \right) ^ d
\end{equation}
(7)二次有理核函数
\begin{equation}
\kappa(x, z) = 1 - \frac{\left|| x - z \right||^2}{\left||x - z \right||^2 + c}
\end{equation}
(8)多元二次核函数
\begin{equation}
\kappa(x, z) = \sqrt{\left|| x - z \right||^2 + c^2}
\end{equation}
(9)逆多元二次核函数
\begin{equation}
\kappa(x, z) = \frac{1}{\sqrt{\left|| x - z \right||^2 + c^2}}
\end{equation}
(10)sigmoid核函数
\begin{equation}
\kappa(x, z) = \tanh(\alpha x^T + c)
\end{equation}
(11)傅立叶核函数
\begin{equation}
\kappa(x_i, z_j) = \frac{1}{2} + \sum_{k=1}^{N}(\sin(kx_i)\sin(kz_j) + \cos(kx_i)\cos(kz_j))
\end{equation}
注:$d$表示阶数。$d$越大,映射的维度越高,计算量越大,此时容易出现“过拟合现象”。
采用sigmoid作为核函数时,支持向量机实际就是一种多层感知器神经网络。此时,神经网络的隐含层节点数目、隐含层节点对输入节点的权值都是训练过程中自动确定的。支持向量机的理论基础决定了它最终求得的是全局最优值而不是局部最优值,也保证了它对于未知样本的良好泛化性能而不会出现“过拟合”现象。
核函数的选择:在选择核函数解决实际问题时,通常采用的方法有:
(1)利用专家的先验知识预先选定核函数;
(2)采用交叉验证(Cross-validation)方法。即在进行核函数选取时,分别试用不同的核函数,归纳误差最小的核函数就是最好的核函数。如针对傅立叶核、RBF核,结合信号处理问题中的函数回归问题,通过仿真实验,对比分析了在相同数据条件下,采用傅立叶核的SVM要比采用RBF核的SVM误差小很多。
(3)采用由Smits等人提出的混合核函数方法,该方法较之前两者是目前选取核函数的主流方法,也是关于如何构造核函数的又一开创性的工作.将不同的核函数结合起来后会有更好的特性,这是混合核函数方法的基本思想。
答案:B