初识BP
BP(Back Propagation)神经网络是整个深度学习的基础。当前,大多数深度神经网络仍然采用BP作为误差反向传播的技术。通常,BP是指具有三层网络结构的浅层神经网络,如图1。实际上,BP除了输入层和输出层外,只有1层隐藏层,所以它是浅层神经网络。
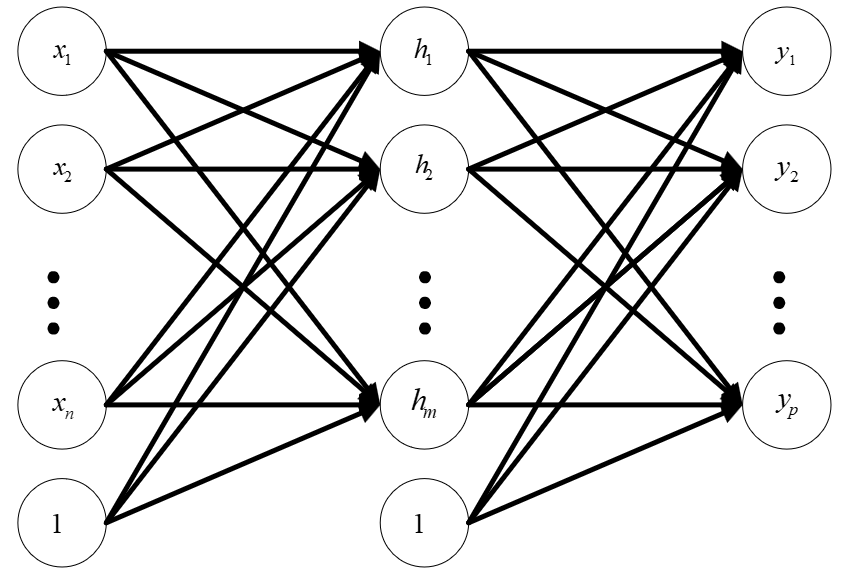 图1 BP神经网络
图1 BP神经网络在正式推导BP的数学表示之前,我们需要先明确一下相关数学符号的意义。
如图1,我们记BP的网络层数为$n_l$,则$n_l=3$。记BP网络的第$l(l=1,2,3)$层为$L_l$。故图1中的输入层、隐层和输出层分别记为$L_1$、$L_2$和$L_3$。 记$L_l$的第$i$个神经元与$L_{l+1}$的第$j$个神经元连接的权重为$W_{ij}^{(l)}$。图1中的$1$是一个偏置项,记$L_l$的偏置项为$b^{(l)}$。
BP前向传播
设$L_l$的第$i$个神经元的输入为$z_i^{(l)}$,$L_l$的第$i$神经元的输出为$a_i^{(l)}$。显然,当$l=1$时,$a_i^{l}=x_i$。假设所使用的激活函数记为$f(x)$。于是,BP的前向传播可如下式计算:
隐层:
\begin{equation}
\begin{split}
z_1^{(2)} &= W_{11}^{(1)}x_1 + W_{21}^{(1)}x_2 + \cdots + W_{n1}^{(1)}x_n + b^{(1)} \\
a_{1}^{(2)} &= f(z_1^{(2)}) = f(W_{11}^{(1)}x_1 + W_{21}^{(1)}x_2 + \cdots + W_{n1}^{(1)}x_n + b^{(1)}) \\
z_2^{(2)} &= W_{12}^{(1)}x_1 + W_{22}^{(1)}x_2 + \cdots + W_{n2}^{(1)}x_n + b^{(1)} \\
a_{2}^{(2)} & = f(z_2^{(2)}) = f(W_{12}^{(1)}x_1 + W_{22}^{(1)}x_2 + \cdots + W_{n2}^{(1)}x_n + b^{(1)}) \\
\vdots \\
z_m^{(2)} &= W_{1m}^{(1)}x_1 + W_{2m}^{(1)}x_2 + \cdots + W_{nm}^{(1)}x_n + b^{(1)} \\
a_m^{(2)} &= f(z_m^{(2)}) = f(W_{1m}^{(1)}x_1 + W_{2m}^{(1)}x_2 + \cdots + W_{nm}^{(1)}x_n + b^{(1)})
\end{split}
\tag{1}
\end{equation}
输出层:
\begin{equation}
\begin{split}
z_1^{(3)} &= W_{11}^{2}a_{1}^{(2)} + W_{21}^{(2)}a_{2}^{(2)} + \cdots + W_{m1}^{(2)}a_{m}^{(2)} + b^{(2)} \\
a_{1}^{(3)} &= f(z_1^{(3)}) = f(W_{11}^{2}a_{1}^{(2)} + W_{21}^{(2)}a_{2}^{(2)} + \cdots + W_{m1}^{(2)}a_{m}^{(2)} + b^{(2)}) \\
z_2^{(3)} &= W_{12}^{2}a_{1}^{(2)} + W_{22}^{(2)}a_{2}^{(2)} + \cdots + W_{m2}^{(2)}a_{m}^{(2)} + b^{(2)} \\
a_{2}^{(3)} &= f(z_2^{(3)}) = f(W_{12}^{2}a_{1}^{(2)} + W_{22}^{(2)}a_{2}^{(2)} + \cdots + W_{m2}^{(2)}a_{m}^{(2)} + b^{(2)}) \\
\vdots \\
z_p^{(3)} &= W_{1p}^{2}a_{1}^{(2)} + W_{2p}^{(2)}a_{2}^{(2)} + \cdots + W_{mp}^{(2)}a_{m}^{(2)} + b^{(2)} \\
a_p^{(3)} &= f(z_p^{(3)}) = f(W_{1p}^{2}a_{1}^{(2)} + W_{2p}^{(2)}a_{2}^{(2)} + \cdots + W_{mp}^{(2)}a_{m}^{(2)} + b^{(2)})
\end{split}
\tag{2}
\end{equation}
我们将上面的输出层的式子用统一的形式表述之。即
\begin{equation}
\hat{y} = f(\sum_{i = 1}^{m}w_{ij}^{(2)}a_i^{(2)} + b^{(2)}), j = 1, 2, \cdots, p
\tag{3}
\end{equation}
反向传播
设有$s$个训练样本${(X^{(1)}, y^{(1)}), (X^{(2)}, y^{(2)}), \cdots, (X^{(s)}, y^{(s)})}$。对于训练样本$(X, y)$,其损失函数为:
\begin{equation}
L(W, b) = \frac{1}{2} \left|| \hat{y}- y \right||^2
\tag{4}
\end{equation}
通常,为了防止模型过拟合,损失函数会加上正则项$R$。即
\begin{equation}
L(W, b) = L(W, b) + R
\tag{5}
\end{equation}
其中$R$为:
\begin{equation}
R = \frac{\lambda}{2}\sum_{l=1}^{n_l - 1}\sum_{i = 1}^{q_l}\sum_{j = 1}^{q_{l + 1}}(W_{ij}^{(l)})
\tag{6}
\end{equation}
这里的$q_l$表示第$L_l$上的神经元数量。所以最终的损失函数$L$可形式化为:
\begin{equation}
L(w, b) = \frac{1}{s}\sum_{i = 1}^{s}L(W, b) + \frac{\lambda}{2}\sum_{l=1}^{n_l - 1}\sum_{i = 1}^{q_l}\sum_{j = 1}^{q_{l + 1}}(W_{ij}^{(l)})
\tag{7}
\end{equation}
其中$\lambda$为正则化率。
为使损失函数$L(w, b)$得到最小值,我们需要通过梯度下降来调整权重$W$以及偏置项$b$。其数学表述如下:
\begin{equation}
\begin{split}
W_{ij}^{(l)} &= W_{ij}^{(l)} -\alpha \frac{\partial}{\partial W_{ij}^{(l)}} L(W, b) \\
b_{i}^{(l)} &= b_{i}^{(l)} - \alpha \frac{\partial}{\partial b_{i}^{(l)}} L(W, b)
\end{split}
\tag{8}
\end{equation}
其中$\alpha$称为学习率。
我们对$(7)$式分别对$W$和$b$求偏导:
\begin{equation}
\begin{split}
\frac{\partial}{\partial W_{ij}^{(l)}}L(W, b) &= \frac{1}{s}\sum_{i = 1}^{s}\frac{\partial}{\partial W_{ij}^{(l)}}L(W, b) + \lambda W_{ij}^{(l)} \\
\frac{\partial}{\partial b_i^{(l)}}L(W, b) &= \frac{1}{s}\sum_{i = 1}^{s}\frac{\partial}{\partial b_i^{(l)}}L(W, b)
\end{split}
\tag{9}
\end{equation}