主题模型产生的背景
传统的信息检索(Information Retrieve)系统中通常使用文档相似性来判别查询(Query)与海量文本的相似性来得到两者之间的关联程度。然而,这种方法只能从文字表面得出query与查询文本之间的相似度,不能够表征两者之间语义上的关联。因此,基于这种文档相似度的方法的信息检索的返回字面上高度相似但语义不相关联的结果。为了解决这一问题,能够表征语义关联的主题模型就被提出来了。
在自然语言理解的任务中,可以从文本的不同粒度(字符级、词级、句子级、段级和文档级)提取语义。主题模型就是一种能够从文档级表征文本语义的模型。主题建模就是在文档集合中学习、识别和提取主题的过程。
主题模型基于两个相同的假设:
(1)每个文档包含多个主题;
(2)每个主题含有多个单词。
实际上,文档的语义由一些隐变量(或潜在变量)管理。主题模型的目标就是揭示这些潜在变量,即主题。主题塑造了文档和语料库的含义。本文介绍常用的主题模型:LSA(Latent Semantic Analysis),pLSA(probability Latent Semantic Analysis),LDA(Latent Dirichlet Allocation)和LDA2Vec。
LSA:潜在语义分析
LSA的核心思想是把我们所拥有的文档-术语矩阵分解成相互独立的文档-主题和主题-术语矩阵。
对于一个给定的语料库,假设该语料库中有$m$个文档,每个文档有$n$个单词。于是我们可以由此构造规模为$m\times n$的文档-术语矩阵$A$,其中行表示一篇文档,列表示该文档存在的单词。$A$中的元素$a_{ij}$可以由两种方式来确定:
(1)$a_{ij}$是$j$个词在$i$篇文档中的频度;
(2)$a_{ij}$用TF-IDF(Term Frequency–Inverse Document Frequency,词频-逆文本频率指数)来表示。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
由上述方式构造出来的文档-术语矩阵是一个规模庞大但稀疏的矩阵,维度存在冗余。为了找出能够捕捉单词和文档关系的少数潜在主题,有必要降低$A$的维度。
我们使用SVD(Singular Value Decomposition,奇异值分解)截断来对$A$进行降维。SVD会将$A$分解成三个独立的矩阵的乘积,即$A = U \Lambda V$。其中$Lambda$是$A$的对角阵,称为奇异值,$U$称为文档-主题矩阵,$V$称为术语-主题矩阵。
截断SVD的降维方式是:
选择奇异值$\Lambda$中最大的$t$个数,且只保留矩阵$U$和$V$中的前$t$列。其中$t$是一个可以根据主题数量进行选择和调整的超参数。
我们以数据集20_newsgroup为例来简单体会一下LSA用来建模主题。在正式引入源码之前先介绍一下20_newsgroup数据集。20 newsgroups数据集18000篇新闻文章,一共涉及到20种话题,所以称作20 newsgroups text dataset,分为两部分:训练集和测试集,通常用来做文本分类。20种话题如下:
- alt.atheism
- comp.graphics
- comp.os.ms-windows.misc
- comp.sys.ibm.pc.hardware
- comp.sys.mac.hardware
- comp.windows.x
- misc.forsale
- rec.autos
- rec.motorcycles
- rec.sport.baseball
- rec.sport.hockey
- sci.crypt
- sci.electronics
- sci.med
- sci.space
- soc.religion.christian
- talk.politics.guns
- talk.politics.mideast
- talk.politics.misc
- talk.religion.misc
LSA源码
1 | import numpy as np |
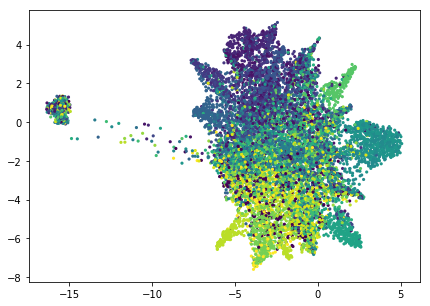 图1 LSA主题模型可视化
图1 LSA主题模型可视化LSA是以共现表(文档-术语矩阵)的奇异值分解形式实现的,是用于小规模数据集,可用于文档分类/聚类、同义词/多义词检索、跨语言检索。SVD的计算是一个十分耗时的过程,并且潜在语义数量$t$的选择对结果的影响很大。此外,LSA的原理简单但得到的不是概率模型,缺乏统计基础,矩阵种的负值难以解释,难以对应到现实中的概念。
pLSA: 概率潜在语义分析
pLSA是基于派生自LCM(least common multiple,最小公倍数)的混合矩阵分解,属于概率图模型(probabilistic graphical model,概率图模型是用图来表示变量概率依赖关系的理论,结合概率论与图论的知识,利用图来表示与模型有关的变量的联合概率分布)中的生成模型。生成式模型的代表是:一元模型(Unigram Model)、混合一元模型、n元语法模型、隐马尔可夫模型、朴素贝叶斯模型等。判别式模型的代表是:最大熵模型、支持向量机、条件随机场、感知机模型等。pLSA 模型是有向图模型,将主题作为隐变量,构建了一个简单的贝叶斯网,采用EM(Expectation-Maximization)算法估计模型参数。
多项式分布:
若伯努利分布由单变量扩展到$d$维的向量$x_i$,$x_i={0,1}$且$\sum_{i = 1}^{d}x_i = 1$。进一步,假设$x_i$取$1$得概率为$\mu_i \in \sum_{i = 1}^{d} \mu_i = 1$。则:
\begin{equation}
\begin{split}
P(x|\mu) &= \Pi_{i = 1}^{d} \mu_i^{x_i} \\
\mathbb{E}[X_i] &= \mu_i \\
D[X_i] &= \mu_i(1-\mu_i)
\end{split}
\tag{1}
\end{equation}
将二项分布扩展到多项分布(multinomial distribution)。多项分布描述在$N$次独立实验中有$m_i$次$x_i = 1$的概率。
\begin{equation}
\begin{split}
P(m_1,\cdots,m_d| N, \mu) = \frac{N!}{m_1!\cdots m_d!}\Pi_{i=1}^{d}\mu_i^{m_i}
\end{split}
\tag{2}
\end{equation}
一元模型假设每篇文档中的词出现的次数服从多项式分布(式2)。pLSA模型中引入了隐变量z作为潜在语义,并使用EM算法对潜在语义模型进行拟合。pLSA的概率图模型如图2所示。
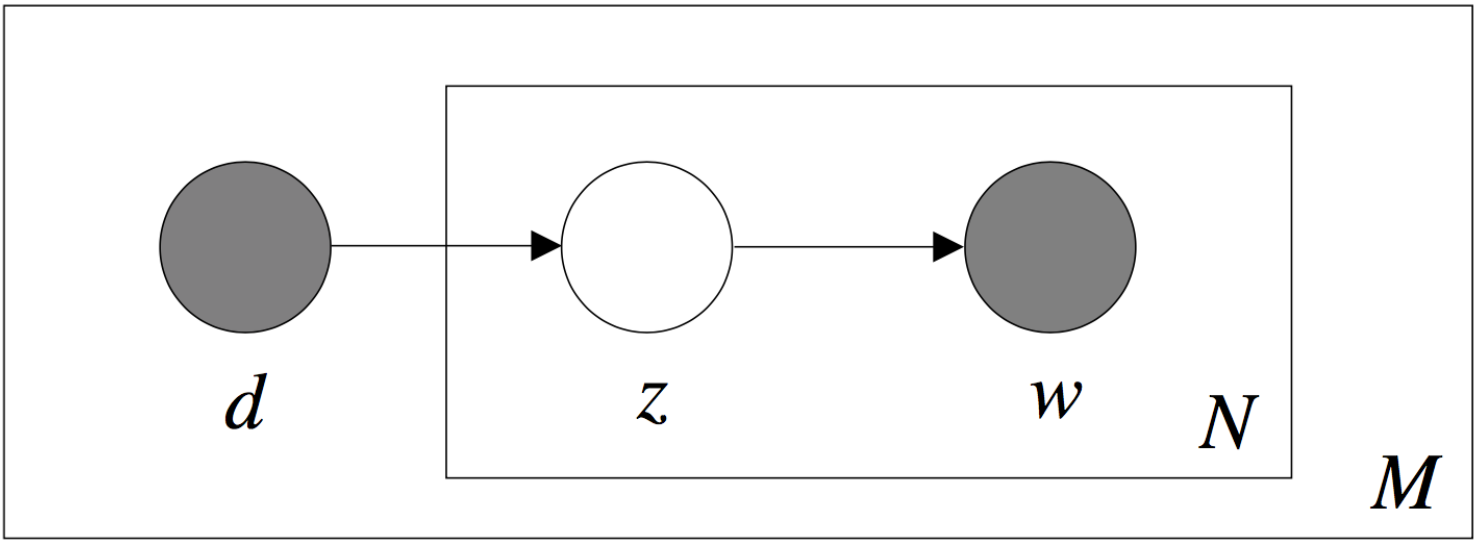 图2 pLSA主题模型概率图
图2 pLSA主题模型概率图pLSA主题模型概率图参数说明: 外部大方框表示有$M$篇文档的文档集,内部小方框表示每篇文档集的文档长度为$N$。每篇文档记为$d_m(d_m \in \mathbb{D}, m = 1, 2, \cdots, M)$, 其中$\mathbb{D}$记为文档集。$z_k(z_k \in \mathbb{Z^+}, k = 1, 2, \cdots, K)$是一个隐变量,表示主题,其中$K$表示主题总数,$Z^+$表示整数集。词$w_n \in \mathbb{W}(n = 1, 2, \cdots, V)$, 其中$\mathbb{W}$表示词汇表, $V$表示词汇表的规模。
给定一个文档集$\mathbb{D}$, 我们可以得到一个词-文档共现矩阵,该矩阵的每个元素$n(d_m, w_n)$表示词$w_n$在文档$d_m$中的词频。pLSA对主题建模的过程如下:
(1)以概率$P(d_m)$选择一篇文档$d_m$;
(2)以概率$P(z_k|d_m)$得到主题$z_k$;
(3)以概率$P(w_n|z_k)$生成一个词$w_n$。
pLSA的参数$\theta$是:$K \times M$个$P(z_k|d_m)$和$V \times K$个$P(w_n|z_k)$。具体地:$P(z_k|d_m)$表征的是给定文档在各个主题下的分布情况下,文档在全部主题上服从多项式分布,共$M$个,$P(w_n|z_k)$表征的是给定主题词语分布情况下,主题在全部词语上服从多项式分布, 共$K$个。
根据pLSA建模的过程,我们可以得到贝叶斯网表达的联合分布为:
\begin{equation}
P(d_m,z_k,w_n)=P(d_m)P(z_k|d_m)P(w_n|z_k)
\end{equation}
该联合分布表示的含义就是pLSA建模的过程。
于是,一个词$w_n$出现在文档$d_m$的联合分布为:
\begin{equation}
P(d_m,w_n)=P(d_m)P(w_n|d_m)
\end{equation}
进一步,我们根据给定文档集$D$,生成一篇文档$\overset{\rightarrow}{w}=(w_1, w_2, \cdots, w_N)$的概率为:
\begin{equation}
P(\vec{w}|d_m)=\prod_{n=1}^N P(w_n|d_m)
\end{equation}
条件独立性: 如果$P(X, Y|Z) = P(X|Z)P(Y|Z)$(等价地$P(X|Y,Z) = P(X|Z)$),则称事件$X,Y$对于给定事件$Z$是条件独立的。即: 当$Z$发生时,$X$发生与否与$Y$发生与否是无关的。
全概率公式: 设$B_1, B_2, \cdots$是样本空间$\Omega$的一个划分, $A$为任一事件,则:
\begin{equation}
P(A) = \sum_{i = 1}^{\infty}P(B_i)P(A|B_i)
\end{equation}
因此,我们可以引入一个隐变量$z_k$(实际上,$z_k$就是主题),在不考虑随机变量之间的随机独立性,则可以得到用$z_k$表示的$P(\vec{w}|d_m)$。
\begin{equation}
P(w_n|d_m)=\sum_k P(z_k|d_m)P(w_n|z_k,d_m)
\end{equation}
上式表明,一篇文档是根据特定主题把词聚集在一起的。
pLSA的概率图模型是典型的head-to-tail情况。故当$z$已知时,$d$和$w$条件独立,即:
\begin{equation}
P(w_n|z_k,d_m)=P(w_n|z_k)
\end{equation}
进一步:
\begin{equation}
P(w_n|d_m)=\sum_k P(z_k|d_m)P(w_n|z_k)
\end{equation}
所以:
\begin{equation}
P(d_m,w_n)=P(d_m)\sum_k P(z_k|d_m)P(w_n|z_k)
\end{equation}
此时,我们就可以pLSA建模转化为从文档集$\mathbb{D}$中估计上式的参数:$P(z_k|d_m)$和$P(w_n|z_k)$。
考虑最大似然函数法用来估计参数:
\begin{equation}
\begin{aligned}
L(\theta)&=\ln \prod_{m=1}^M\prod_{n=1}^N P(d_m,w_n)^{n(d_m,w_n)}\\
&=\sum_m\sum_n n(d_m,w_n)\ln P(d_m,w_n)\\
&=\sum_m\sum_n n(d_m,w_n)\ln \left[P(d_m)P(w_n|d_m)\right] \\
&=\sum_m\sum_n n(d_m,w_n)(\ln P(d_m)+\ln P(w_n|d_m))\\
&=\sum_m\sum_n n(d_m,w_n)\ln P(w_n|d_m)+\sum_m\sum_n n(d_m,w_n)\ln P(d_m)
\end{aligned}
\end{equation}
我们进一步简化上式:
对于上式的第二项$\sum_m\sum_n n(d_m,w_n)\ln P(d_m)$:
因为:
\begin{equation}
\sum_m\sum_n n(d_m,w_n)\ln P(d_m) = \sum_{m}P(d_m)\sum_{n}n(d_m, w_n)
\end{equation}
显然地,对于给定文档集$\mathbb{D}$, $\sum_{n}n(d_m, w_n)$是一个常数,记为$C$。于是:
\begin{equation}
\begin{split}
\sum_m\sum_n n(d_m,w_n)\ln P(d_m) &= \sum_{m}P(d_m)\sum_{n}n(d_m, w_n) \\
&= C\sum_{m}P(d_m)
\end{split}
\end{equation}
又因为$P(d_m)$为在文档集$D$中选择某个文档的概率,故$\sum_{m}P(d_m)=1$。所以:
\begin{equation}
\begin{split}
\sum_m\sum_n n(d_m,w_n)\ln P(d_m) &= \sum_{m} P(d_m) \sum_{n} n(d_m, w_n) \\
&= C \sum_{m} P(d_m) \\
&= C
\end{split}
\end{equation}
如此一来,$L(\theta)$即为:
\begin{equation}
\begin{aligned}
L(\theta)&=\ln \prod_{m=1}^M\prod_{n=1}^N P(d_m,w_n)^{n(d_m,w_n)}\\
&=\sum_m\sum_n n(d_m,w_n)\ln P(d_m,w_n)\\
&=\sum_m\sum_n n(d_m,w_n)\ln \left[P(d_m)P(w_n|d_m)\right] \\
&=\sum_m\sum_n n(d_m,w_n)(\ln P(d_m)+\ln P(w_n|d_m))\\
&=\sum_m\sum_n n(d_m,w_n)\ln P(w_n|d_m)+\sum_m\sum_n n(d_m,w_n)\ln P(d_m) \\
&=\sum_m\sum_n n(d_m,w_n)\ln P(w_n|d_m) + C
\end{aligned}
\end{equation}
要求$L(\theta)$的最大值,可转化为求$\sum_m\sum_n n(d_m,w_n)\ln P(w_n|d_m)$的最大值。
我们不妨新令$L(\theta)=\sum_m\sum_n n(d_m,w_n)\ln P(w_n|d_m)$。
\begin{equation}
\begin{aligned}L(\theta)&=\sum_m\sum_n n(d_m,w_n)\ln P(w_n|d_m)\\
&=\sum_m\sum_n n(d_m,w_n)\ln \bigl[\sum_k P(z_k|d_m)P(w_n|z_k)\bigr]\end{aligned}
\end{equation}
直接对$L(\theta)$求偏导以获取最值点的方法难以在该问题中实现。于是我们引入EM法来求解$L(\theta)$的参数。