RNN的结构
RNN的折叠结构与展开结构如图1所示。
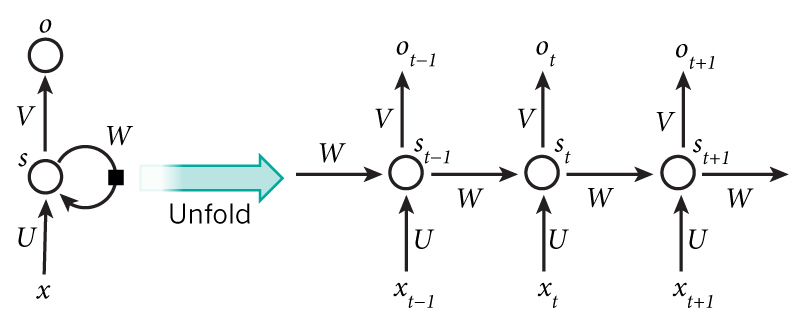 图1 RNN的折叠结构与展开结构
图1 RNN的折叠结构与展开结构RNN的Cell如图2所示。
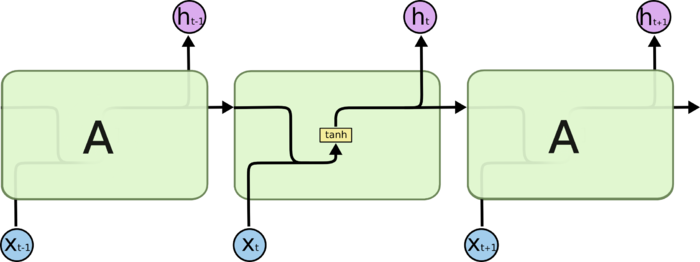 图2 RNN单元
图2 RNN单元序列经过RNN通过式(1)处理:
\begin{equation}
\begin{split}
h_t = \tanh (W \cdot [h_{t-1}, x_t] + b_0)
\end{split}
\tag{1}
\end{equation}
RNN是在随时间传递的神经网络,其深度即为时间的长度。因此,随着时间变长,神经网络逐渐加深,于是当将BPTT应用于较深的RNN时,会产生“梯度消失”问题。
梯度消失:在训练神经网络过程中,神经网络权重的更新值与误差函数梯度成正比。然而在某些情况下(如RNN等这类超深的神经网络中),梯度值会几乎消失,使得权重无法更新,甚至导致神经网络完全无法继续训练。 这种现象称为梯度消失。
为解决“梯度消失”问题,研究者改进了RNN,从而产生了LSTM。
LSTM的结构
LSTM的结构如图3所示:
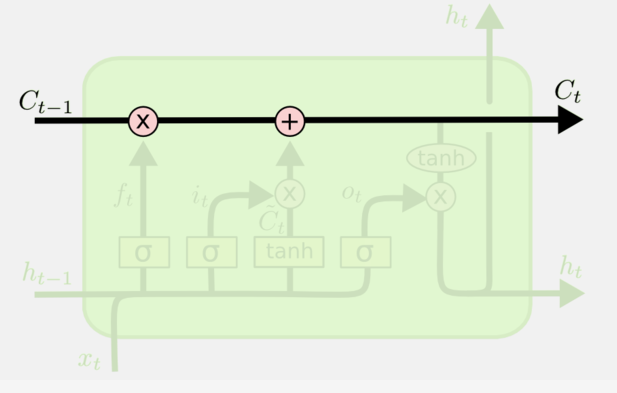 图3 LSTM单元
图3 LSTM单元LSTM的表达式:
\begin{equation}
\begin{split}
f_t &= \sigma(W_f \cdot [h_{t - 1}, x_t] + b_f) \\
i_t &= \sigma(W_i \cdot [h_{t - 1}, x_t] + b_i) \\
\overset{\sim}{C}_t &= \tanh(W_C \cdot [h_{t - 1}, x_t] + b_C) \\
C_t &= f_t \times C_{t-1} + i_t \times \overset{\sim}{C}_t \\
o_t &= \sigma(W_o \cdot [h_{t - 1}, x_t] + b_o) \\
h_t &= o_t \times \tanh(C_t)
\end{split}
\tag{2}
\end{equation}
LSTM有通过精心设计的称作“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。它们包含一个sigmoid神经网络层和一个pointwise乘法(点乘)操作。Sigmoid层输出0到1之间的数值,描述每个部分有多少量可以通过。 0代表“不许任何量通过”;1代表“允许任何量通过” 。LSTM 拥有三个门,来保护和控制细胞状态,分别是:遗忘门、输入门、输出门。在输出门前面会进行当前时间的细胞状态更新。每一个状态会传递一个隐藏层特征和细胞状态特征给下一个状态。
GRU的结构
GRU的结构如图4所示:
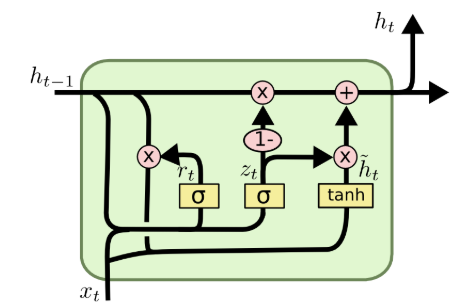 图4 GRU单元
图4 GRU单元GRU与LSTM相似。与LSTM相比,GRU去除掉了细胞状态。使用隐藏状态来进行信息的传递。GRU只包含两个门:更新门和重置门。更新门的作用类似于 LSTM 中的遗忘门和输入门。它决定了要忘记哪些信息以及哪些新信息需要被添加;重置门用于决定遗忘先前信息的程度。GRU 的张量运算较少,因此它比 LSTM 的训练更快一下。
GRU的表达式:
\begin{equation}
\begin{split}
z_t &= \sigma(W_z \cdot [h_{t-1}, x_t]) \\
r_t &= \sigma(W_r \cdot [h_{t-1}, x_t]) \\
\overset{\sim}{h}_t &= \tanh(W\cdot [r_t\times h_{t-1}, x_t]) \\
h_t &= (1 - z_t) \times h_{t-1} + z_t \times \overset{\sim}{h}_t
\end{split}
\tag{3}
\end{equation}
SRU的结构
SRU的结构如图5所示:
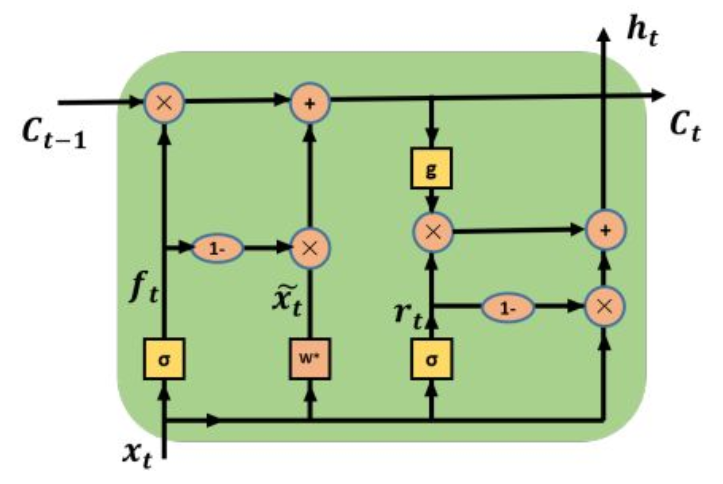 图5 SRU单元
图5 SRU单元\begin{equation}
\begin{split}
\overset{\sim}{x_t} &= Wx_t \\
f_t &= \sigma(W_f x_t + b_f) \\
r_t &= \sigma(W_r x_t + b_r) \\
c_t &= f_t \odot c_{t-1} + (1 - f_t) \odot \overset{\sim}{x}_t \\
h_t &= r_t \odot g(c_t) + (1 - r_t) \odot x_t
\end{split}
\tag{4}
\end{equation}
其中,f表示forget gate,r表示 reset gate,h表示output state,c表示internal state。x表示输入。