基于距离度量相似性的聚类算法的缺点
k-means算法、k-means++算法和mean shift都是基于距离的聚类算法。基于距离的聚类算法的聚类结果是球状的簇,当数据集中的聚类结果是非球状结构时,基于距离的聚类算法的聚类效果很差。于是,为解决基于距离的聚类算法不能够对非球状的数据进行很好聚类的缺点,基于密度的聚类算法就被提出来了。居于密度的聚类算法可以发现任意形状的聚类。
基于密度的聚类算法是通过在数据集中寻找被低密度区域分离的高密度区域,将分离出的高密度区域作为一个独立的类别。DBSCAN是一种典型的基于密度的聚类算法。
DBSCAN的算法原理
基本概念
DBSCAN中有两个基本的邻域参数分别为$\varepsilon$和$MinPts$。 $\varepsilon$表示数据集$D$中与样本点$x_i$的距离不大于$\varepsilon$的样本,即
\begin{equation}
N_{\varepsilon} (x_i) = \left\{ x_j \in D | dist(x_i, x_j) \le \varepsilon \right\}
\tag{1}
\end{equation}
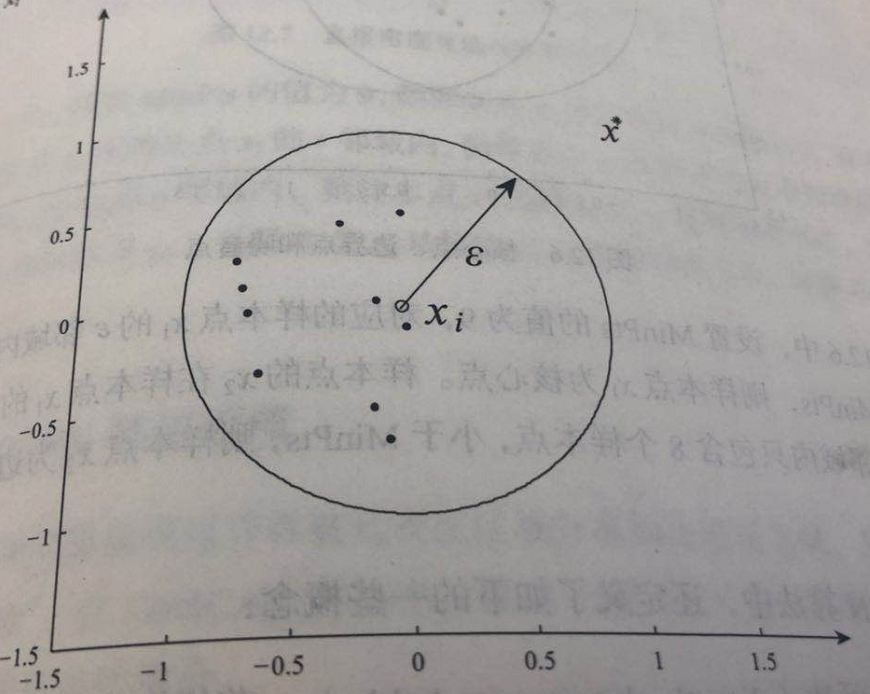 图1 $x_i$的$\varepsilon$邻域
图1 $x_i$的$\varepsilon$邻域在图1中,样本点$x^\star$不在样本点$x_i$的$\varepsilon$邻域内。
$x_i$的密度可由$x_i$的$\varepsilon$邻域内的点的数量来估计。$MinPts$表示样本点$x_i$的$\varepsilon$邻域内的最少样本点的数目。基于邻域参数$\varepsilon$邻域和$MinPts$,在DBSCAN算法中将数据点分为一下三类:
- 核心点:若样本$x_i$的$\varepsilon$邻域内至少包含$MinPts$个样本,即$\left| N_{\varepsilon} (x_i) > MinPts \right|$,则称样本点$x_i$的核心点。
- 边界点:若样本$x_i$的$\varepsilon$邻域内包含的样本数目小于$MinPts$,但是$x_i$在其他核心点的领域内,则称样本点$x_i$为边界点。
- 噪音点:既不是核心点也不是边界点的点称为噪音点。
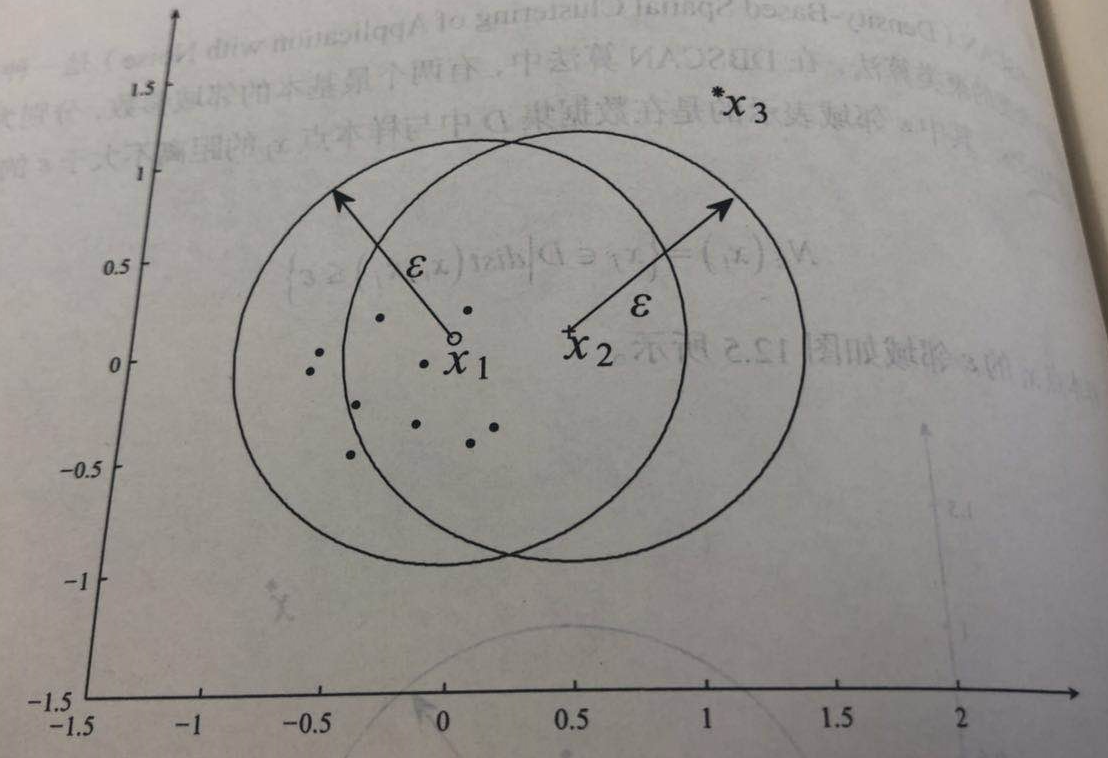 图2 核心点、边界点和噪音点
图2 核心点、边界点和噪音点- 直接密度可达:若样本点$x_j$在核心点$x_i$的$\varepsilon$邻域内 ,则称样本点$x_j$从样本点$x_i$直接密度可达。
- 密度可达:若样本点$x_{i, 1}$和样本点$x_{i, n}$之间存在序列$x_{i, 2}, x_{i, 3}, \cdots, x_{i, n - 1}$,且$x_{i, j + 1}$与$x_{i, j}$直接密度可达,则称$x_{i, n}$从$x_{i, 1}$密度可达。
- 密度连接:对于样本点$x_i$和样本点$x_j$,若存在样本点$x_k$使得$x_i$和$x_j$都从$x_k$密度可达,则称$x_i$和$x_j$密度相连。
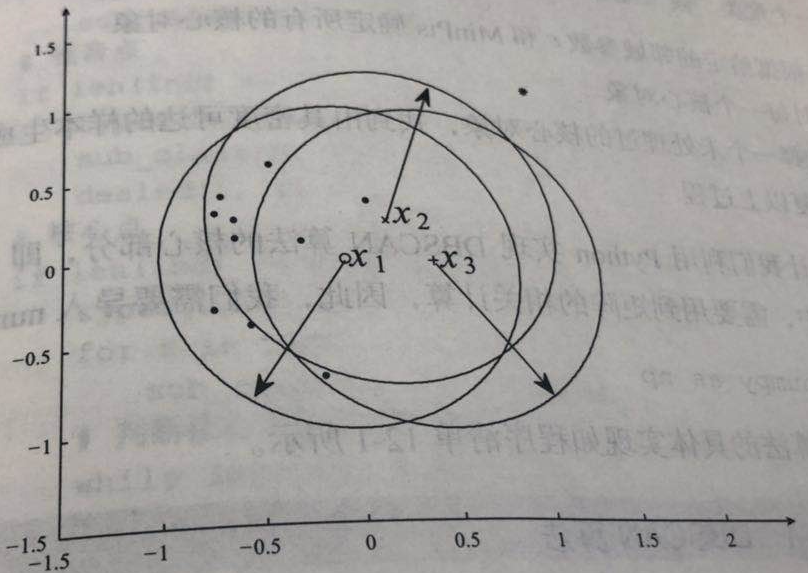 图3 直接密度可达和密度可达
图3 直接密度可达和密度可达算法原理
基于密度的聚类算法通过寻找被低密度区域分离的高密度区域,并将高密度区域作为一个“簇”。在DBSCAN算法中,聚类“簇”定义为:由密度可达关系导出的最大密度连接样本的集合。
若$x$为核心对象,由$x$密度可达的所有样本组成的集合记为:
\begin{equation}
X = \left\{ x^\prime \in D | x^\prime \quad is \quad density \quad reachable \quad from \quad x \right\}
\tag{2}
\end{equation}
则$X$为满足连接性和最大性的“簇”。
算法流程
在DBSCAN算法中,由核心对象出发,找到与该核心对象密度可达的所有样本形成一个聚类“簇”。DBSCAN算法的算法流程为:
- 根据给定的领域参数$\varepsilon$和$MinPts$确定所有的核心对象;
- 对每一个核心对象,选择一个未处理的核心对象,找到由其密度可达的样本生成聚类“簇”;
- 重复上述过程。
k-means与DBSCAN的聚类效果
先随机初始化数据集,并可视化。1
2
3
4
5
6
7
8
9
10import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
x1, y1 = datasets.make_circles(n_samples=5000, factor=.6, noise=0.05)
x2, y2 = datasets.make_blobs(n_samples=1000, n_features=2,
centers=[[1.2, 1.2]], cluster_std=[[.1]], random_state=9)
X = np.concatenate((x1, x2))
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()
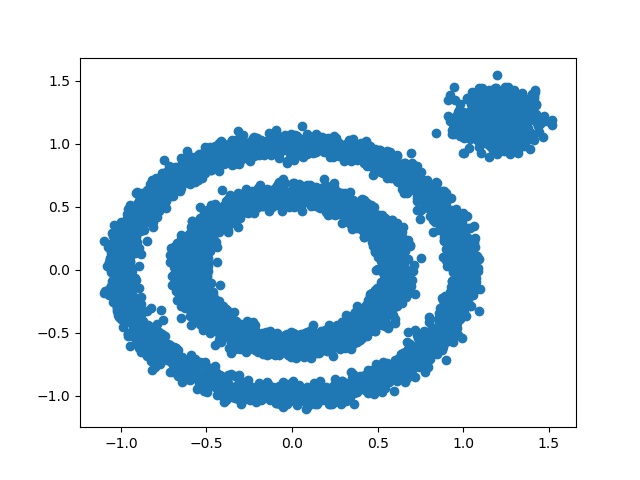 图4 数据分布
图4 数据分布使用k-means来聚类。1
2
3
4from sklearn.cluster import KMeans
y_pred = KMeans(n_clusters=3, random_state=9).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
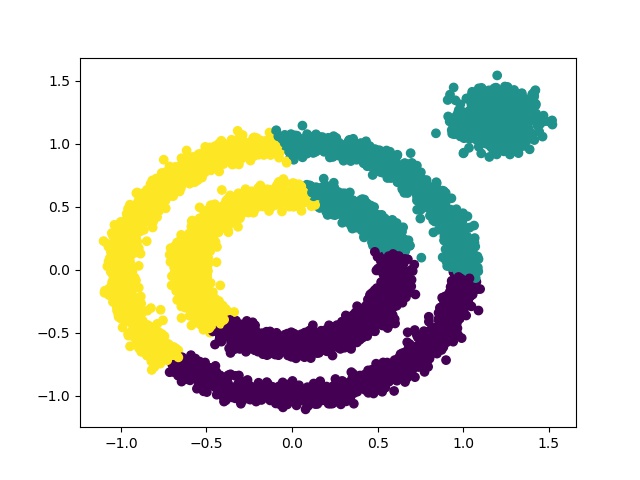 图5 使用k-means来聚类
图5 使用k-means来聚类从图中可以看出,k-means对凸数据集表现良好,而对非凸数据集则表现相对糟糕。
使用DBSCAN来聚类1
2
3
4from sklearn.cluster import DBSCAN
y_pred = DBSCAN(eps = 0.1, min_samples = 10).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
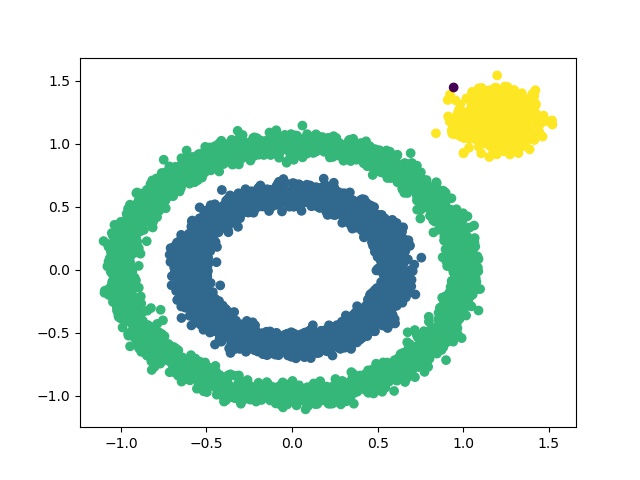 图5 使用DBSCAN来聚类
图5 使用DBSCAN来聚类从图中可以看到,DBSCAN可以对非凸数据集进行比较好的聚类。
完整代码
1 | import numpy as np |