本文是对论文对Multi-Task Deep Neural Networks for Natural Language Understanding的归纳与总结
动机
学习文本的向量空间表示是自然语言理解(Natural Language Understanding, NLU)任务的基础。有两种流行方法可以完成文本的向量表示学习——多任务学习(Multi-Task Learning, MTL)和语言模型预训练(Language Model Pre-Training.)。作者认为,多任务的联合学习可以让在一个任务中学习到的知识有益于其他的任务。此外,作者分析了MTL引起了很多人的兴趣的两个原因:(1)DNN(Deep Neural Network)监督学习要求大量特定任务的标记数据;(2)MTL的使用受益于正规化效应通过避免对特定任务的过拟合,故而能够使得学习到的表示能够普遍适应跨任务。
与MTL相比,语言模型预训练通过利用大量无标记数据学习通用语言表示是有效的。一些突出的例子是ELMo,GPT,BERT等。这些神经网络语言模型都是用无监督目标在文本数据上训练的。作者认为,MTL和语言模型与训练是相互补充的技术,并且可以将它们结合起来一改进文本表示,从而提升不同NLU(Natural Language Understanding)任务的性能。为此,作者将BERT作为已有的MT-DNN的共享的文本编码层,如图1。
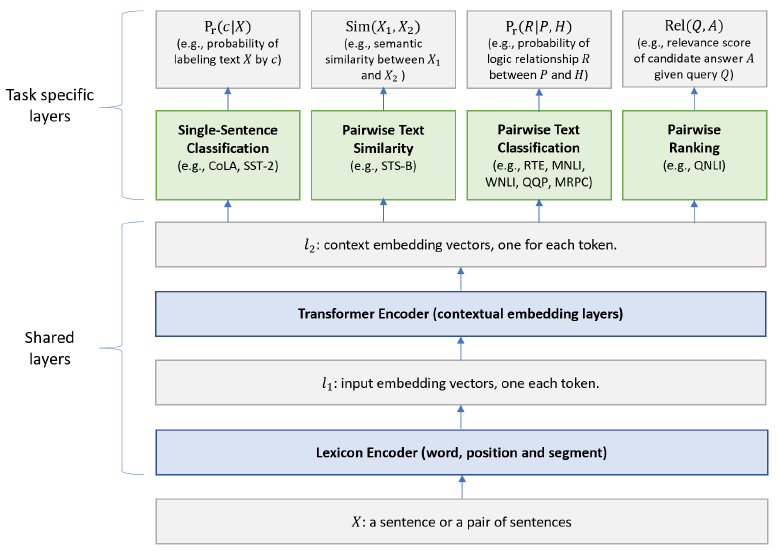 图1 用于表示学习的MT-DNN的架构
图1 用于表示学习的MT-DNN的架构任务
MT-DNN模型结合了四种类型的NLU的任务:单句分类,成对文本分类,文本相似性打分,相关度排名。我们具体介绍这四种类型的任务。
- 单句分类: 给定一个句子,模型要用预定义的类标签标记它。如CoLA任务是要预测一个英语句子是否语法合理的;SST-2任务是要确定来自于观影评价的句子的情感是积极的还是消极的。
- 文本相似性。给定一对句子,模型预测两个句子的语义相似性,是一个回归任务。SST-B在GLUE中仅有的此类任务的例子。
- 成对文本分类:给定一对句子,模型基于预定义的标记集确定两个句子的关系。如RTE和MNLI就是语言推断任务,其目标就是预测一个句子关语另一个是否是一个蕴含,对立或中立的。QQP和MRPC是两个包含了句子对的段落级数据集,该任务是要预测一对段落中的句子是语义等价的。
- 相关度排名: 给定一个查询和候选答案列表,模型对所有候选答案与查询的相关度排序。QNLI涉及到评价是否一个句子包含给定查询的正确的答案。
MT-DNN模型
MT-DNN的模型架构如图1所示,下层被所有的任务共享,而顶层表示特定任务输出。在$l_1$,输出词序列$X$首先被表示一系列嵌入向量,每个词一个向量。然后,Transformer编码器通过self-attention捕捉没个此的上下文信息,并且在$l2$生成一系列上下文嵌入。这就是被多任务目标所共享的语义表示。
词典编码器:输入$X={x_1, \cdots, x_m}$是长度为$m$的一系列token(文本经过分词后产生结果叫做token)。第一个token$x_1$总是[CLS]。如果$X$是一个句子对$(X_1, X_2)$,我们用一个特殊的token——[SEP]来分离两个句子。词典编码器将$X$映射进一系列的输入嵌入向量,每一个token都有一个嵌入向量,嵌入向量是对应的词,分割和位置嵌入的汇总。
Transformer编码器:作者使用了多层双向Transformer编码器以将输入表示向量映射一系列的上下文嵌入向量$\bf C \in \mathbb{R}^{d\times m}$。与BERT模型不同的是,BERT模型通过与训练和通过微调(fine-tuning)来适应每一个单一的任务以学习表示,而MT-DNN是使用多任务目标来学习表示。
单句子分类输出:假设$x$是token——[CLS]的上下文嵌入,其可以被是为输入句子$X$的语义表示。以SST-2作为示例,$X$被标记为类$c$的概率是通过带有$softmax$的逻辑回归预测的:
\begin{equation}
P_r(c|X) = softmax(\bf W^T_{SST} \cdot x)
\tag{1}
\end{equation}
其中$W_{SST}$是特定任务的参数矩阵。
文本相似性输出:以$STS-B$任务作为示例。假定$x$是[CLS]的上下文嵌入,其能够视作输入句子对$(X_1, X_2)$的语义表示。作者引入了特定任务的参数向量$\bf W^T_{SST}$以计算相似性得分:
\begin{equation}
Sim(X_1, X_2) = g(\bf W^T_{SST} \cdot x)
\tag{2}
\end{equation}
其中$g(z)=\frac{1}{1 + \exp{(-z)}}$是sigmoid函数,该函数将得分映射到$[0, 1]$之间的实数值。
成对的文本分类输出:以自然语言推断作为示例(NLI)。NLI任务定义了一个具有$m$个词的前提(premise)$P=(p1,\cdots,p_m)$以及具有$n$个词的假设(hypothesis)$H=(h_1, \cdots, h_n)$,其目的是要找到$P$与$H$之间的逻辑关系$R$。该模块的输出组黁了随机答案网络(Stochastic Answer Network, SAN)。SAN的答案模块使用多步推理,而不是直接预测给定输入的蕴含,其维护了一个状态并且精细地迭代该预测。
SAN的工作流程为:我们通过凭借$P$中词的上下文嵌入(这是Transformer编码器的输出),首先构建前提$P$的working memory,记为$M^p \in \mathbb{R}^{d\times m}$。相似地,假设$H$的working memory记为$M^h \in \mathbb{R}^{d\times n}$。然后,我们进行在memory上进行$K$步推理以输出关系标签,这里的$K$是一个超参数。在开始时,初始状态$s^0$是$M^h$的加权和:
\begin{equation}
s^0 = \sum_j \alpha_jM_j^h$
\tag{3}
\end{equation}
其中$\alpha_j$为:
\begin{equation}
\alpha_j = \frac{\exp(w_1^T\cdot M_j^h)}{\sum_i \exp(w_1^T\cdot M_i^h)}
\tag{4}
\end{equation}
在时间步$k(k\in\{1, 2, \cdots, K - 1 \})$,此时的状态定义为:
\begin{equation}
s^k = GRU(s^{k-1},x^k)
\tag{5}
\end{equation}
这里的$x^k$是由先前的状态$s^{k-1}$和memory $M^p$计算得到的:
\begin{equation}
x^k=\sum_j\beta_j M_j^p
\tag{6}
\end{equation}
且
\begin{equation}
\beta_j = softmax(s^{k-1}\bf W_2^T M^p)
\tag{7}
\end{equation}
一个一层分类器被用来确定第$k$步的关系:
\begin{equation}
P_r^k = softmax(\bf W_3^T [s^k;x^k;|s^k-x^k|;s^k\cdot x^k])
\tag{8}
\end{equation}
每一个$P_r$都是关系$R\in\mathcal{R}$的概率分布。
相关度排名输出:以QNLI作为示例。假设$x$是[CLS]的上下文嵌入向量,该向量是问题和候答案$(Q,A)$的语义关系。作者计算相关度得分:
\begin{equation}
Rel(Q, A) = g(W_{QNLI}^T\cdot x)
\tag{9}
\end{equation}